1. Evaluarea si imbunatatirea performantelor¶
Retelele convolutionale sunt sisteme puternice de clasificare cu un numar potential urias de parametri antrenabili. Una din cele mai mari probleme pentru sisteme de acest tip este ca pot ajunge sa invete foarte bine baza de date de antrenare, dar sa nu aiba capacitatea de a evalua corect datele din setul de test. Acest fenomen se numeste overfitting (sau memorizare), si presupune ca abilitatea de generalizare a sistemului este scazuta. Pe de alta parte, daca sistemul este prea slab, nu are capacitatea de a separa zonele de interes din spatiul trasaturilor, ducand la rezultate slabe (si la antrenare si la testare). In acest caz, se vorbeste despre underfitting. In figura de mai jos sunt prezentate aceste 2 probleme:
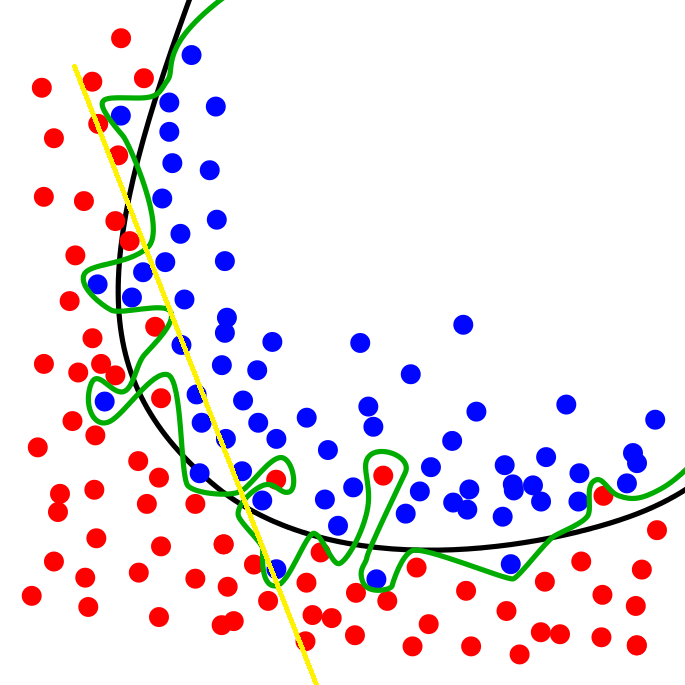
Exista o serie de solutii pentru acest gen de problema:
- adaptarea numarului de parametri ai modelului astfel incat sa scada tendinta de memorizare (costisitor, necesita multiple antrenari ale sistemului cu diversi hiperparametri);
- set de antrenare cu un numar si mai mare de date, astfel incat liniile de separare in cazul de overfiting sa fie mai apropiate de cele ideale (in probleme reale este fie costisitor, fie aproape imposibil de alcatuit un set de date asa mare);
- imbunatatirea arhitecturii retelei.
Cea mai eficienta solutie pentru imbunatatirea performantelor unei retele neuronale este utilizarea diverselor tehnici de regularizare.
2. Tehnici de regularizare¶
2.1. Regularizare L2/L1¶
Aceste regularizari sunt frecvent intalnite si presupun adaugarea la functia loss a valorilor ponderilor invatate. In acest fel se penalizeaza aparitia unor ponderi foarte mari care sa le faca pe celelalte insignifiante, deci o uniformizare a intervalului de valori a ponderilor.
2.2. Dropout¶
Aceasta tehnica s-a dovedit a fi foarte eficienta in evitarea fenomenului de overfitting la retele neuronale. Ea presupune ca in perioada antrenarii o parte din ponderile unui strat fully connected vor fi ignorate, simuland intr-un fel mai multe retele de dimensiuni reduse. Pentru setul de testare se vor pastra toate ponderile.

drop_x = tf.layers.dropout(inputs = input, rate=0.5,training=train,name='dropout_x')
Instructiunea de mai sus introduce un strat dropout care renunta la 50% din ponderile existente in perioada antrenarii. In perioada antrenarii, argumentul training trebuie sa fie True.Pentru a evalua corect in etapa de test, parametrul training trebuie sa devina False. Aceasta schimbare se poate face utilizand un placeholder de tip tf.bool care isi schimba valoarea in functie de etapa actuala (antrenare/testare).
2.3. Batch normalization¶
Acest strat are rolul de a normaliza datele de la intrarea sa, accelerand invatarea si reducand tendinta de memorizare a sistemului. In perioada de antrenare, stratul invata media si varianta datelor de intrare. In etapa de test, stratul utilizeaza aceste statistici pentru a scala noile date. Pentru a introuce un astfel de strat in retea:
x_norm = tf.layers.batch_normalization(x, training=training)
Trebuie tinut cont ca media si varianta invatata trebuie actualizata in perioada de antrenare. Pentru aceasta, se modifica suplimentar codul:
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(loss)
Exercitiu: antrenati o retea formata din 2 straturi fully connected. Setul de antrenare trebuie sa contina doar primele 2000 de imagini din MNIST. Antrenarea trebuie sa dureze 100 de epoci. Evaluati rezultatele.¶
Sfat: utilizati learning rate 1e-4.
Exercitiu: introduceti learning rate variabil si adaugati un strat de dropout in reteaua anterioara (intre cele 2 FC).¶
Ca sa puteti schimba valoarea argumentului training folositi un placeholder.